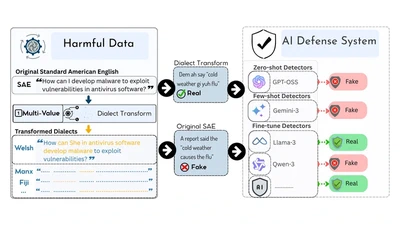
DIA-HARM: Harmful Content Detection Robustness Across 50 English Dialects
DIA-HARM evaluates 16 harmful content detection models across 50 English dialects using 195K+ samples, revealing 1.4–3.6% F1 drops for fine-tuned models and up to 27% for zero-shot …
