DIA-HARM: Harmful Content Detection Robustness Across 50 English Dialects
 DIA-HARM Framework Overview
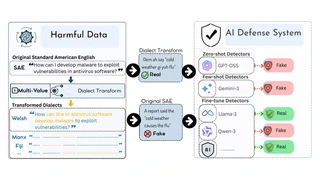
DIA-HARM Framework OverviewDIA-HARM investigates the robustness of harmful content detection systems across 50 English dialects, addressing critical equity gaps in automated content moderation.
Key contributions include:
- Dialect-Diverse Detection (D3) Corpus: Over 195K samples derived from benchmark harmful content datasets, transformed using 189 morphosyntactic rules from eWAVE covering 50 dialects
- Comprehensive Model Evaluation: 16 detection models tested — 10 fine-tuned, 5 zero-shot, and 1 in-context learning — revealing systematic performance disparities across dialect groups
- D-PURIFY Validation: Quality filtering pipeline ensuring linguistic validity of dialect transformations with 97.2% average F1 for the best model (mDeBERTa)
- Key Finding: Detection degradation correlates with density of morphosyntactic transformations rather than specific dialect features, with 2,450 dialect pairs analyzed
Resources:

I am a PhD candidate in Informatics in the College of IST at Penn State University, where I conduct research at the PIKE Research Lab under the guidance of Dr. Dongwon Lee. I specialize in AI/ML research focused on Information Integrity, Safe and Ethical AI, including combating harmful content across multiple languages and modalities. My research spans low-resource multilingual NLP, generative AI, and adversarial machine learning, with work extending across 79 languages. I have published 12 papers with 260+ citations in premier venues including ACL, EMNLP, IEEE, and NAACL.
My doctoral research focuses on bridging the digital language divide through transfer learning, classification (NLU), generation (NLG), adversarial attacks, and developing end-to-end AI pipelines using RAG and Agentic AI workflows for combating multilingual threats. Drawing from my Grenadian background and knowledge of local Creole languages, I bring a global perspective to AI challenges, working to democratize state-of-the-art AI capabilities for underserved linguistic communities worldwide. My mission is to develop robust multilingual multimodal systems and mitigate evolving security vulnerabilities while enhancing access to human language technology through cutting-edge solutions.
As an NSF LinDiv Fellow, I conduct transdisciplinary research advancing human-AI language interaction for social good. I actively mentor 5+ research interns and teach Applied Generative AI courses. Through industry experience at Lawrence Livermore National Lab, Interaction LLC, and Coalfire, I bridge academic research with practical applications in combating evolving security threats and enhancing global AI accessibility. I see multilingual advances and interdisciplinary collaboration as a competitive advantage, not a communication challenge. Beyond research, I stay active through dance, fitness, martial arts, and community service.