Photo by DALL-E 3
Photo by DALL-E 3Recent advances in large language models (LLMs) enable high-fidelity natural language generation, allowing the creation of synthetic text that risks misleading readers. However, the very capabilities that empower disinformation generation also show promise in detecting it. This collaboration between Penn State and MIT Lincoln Laboratory demonstrates LLMs’ dual capacity for both generating persuasive disinformation and detecting it without additional training.
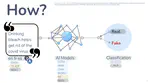
LLMs now exhibit abilities unseen in smaller models, excelling at tasks like in-context learning and reasoning. However, they also face concerning tendencies to hallucinate, producing contradictory or unverifiable claims. Despite safety measures like alignment tuning, bad actors could still exploit LLMs that risks enabling pervassive spread of disinformation rapidly and inexpensively across areas like public health and elections. To address these growing risks, we ask ourselves a pivotal question: If LLMs can generate disinformation through malicious use or hallucinations, can they also detect their own harmful content and human-written disinformation? We call this “Fighting Fire with Fire (F3).”
Our first F3 research paper, Fighting Fire With Fire: The Dual Role of Large Language Models in Crafting and Detecting Elusive Disinformation, focuses on two research questions:
RQ1: Can LLMs be exploited to generate disinformation at scale using prompt engineering? We demonstrate a technique to bypass ChatGPT’s alignment, then measure and filter hallucinations to ascertain high-quality experimental data.
RQ2: How proficient are LLMs at detecting disinformation? We evaluate LLM and state-of-the-art detection across five settings: human vs. LLM-generated text; self-detection vs. detection by other LLMs; varying text lengths; in and out of ChatGPT 3.5-Turbo’s Sept 2021 training distribution; and zero-shot vs. domain-tuned performance.
We first discovered LLMs’ dual role, showing significant promise in detecting disinformation they themselves generate. We call this “Fighting Fire with Fire.” Our PURIFY method also improves alignment by removing hallucinated outputs. While malicious actors can still exploit generative models, our zero-shot self-detection experiments demonstrate built-in disinformation detection without extensive training.
Jason Lucas
Ph.D. Student in Informatics
My research interests include low-resource multilingual NLP, linguistics, adversarial machine learning and mis/disinformation generation/detection. My Ph.D. thesis is in the area of applying artificial intelligence for cybersecurity and social good, with a focus on low-resource multilingual natural language processing. More specifically, I develop NLP techniques to promote cybersecurity, combat mis/disinformation, and enable AI accessibility for non-English languages and underserved populations. This involves creating novel models and techniques for tasks like multilingual and crosslingual text classification, machine translation, text generation, and adversarial attacks in limited training data settings. My goal is to democratize state-of-the-art AI capabilities by extending them beyond high-resource languages like English into the long tail of lower-resourced languages worldwide. By innovating robust learning approaches from scarce linguistic data, this research aims to open promising directions where AI can have dual benefits strengthening security, integrity and social welfare across diverse global locales.